大家好,我大概简单的介绍一下,我叫饶军,我是硅谷的初创公司Confluent的联合创始人之一,我们公司的三个创始人最开始都是在领英这个公司做kafka开发出身的。我们公司是2014年成立的,成立的宗旨想把公司做成一个帮助各种各样企业做基于kafka之上的数据流的事情。
2010的领英

在开始之前,我想大概做一个简单的调查,在座的有谁用过Kafka。大概有80%的人都用了。好,谢谢。今天跟大家分享,想分享一下我们的项目,Kafka的发展,它是怎么创建起来的,然后他的一些经历。说起Kafka的话,那就要回朔到2010年,在这个领域,我是在2010年加入领英,可能很多人都熟悉,这是一个提供人才和机会的社交平台。在2010年的时候,领英初具了一点规模,这也是领英高速成长的一个阶段。在2010年我加入领英的时候大概是600号员工,我是2014年离开领英,离开的时候已经发展到6000号员工,在短短的四年的过程这个组织高速发展。
数据驱动
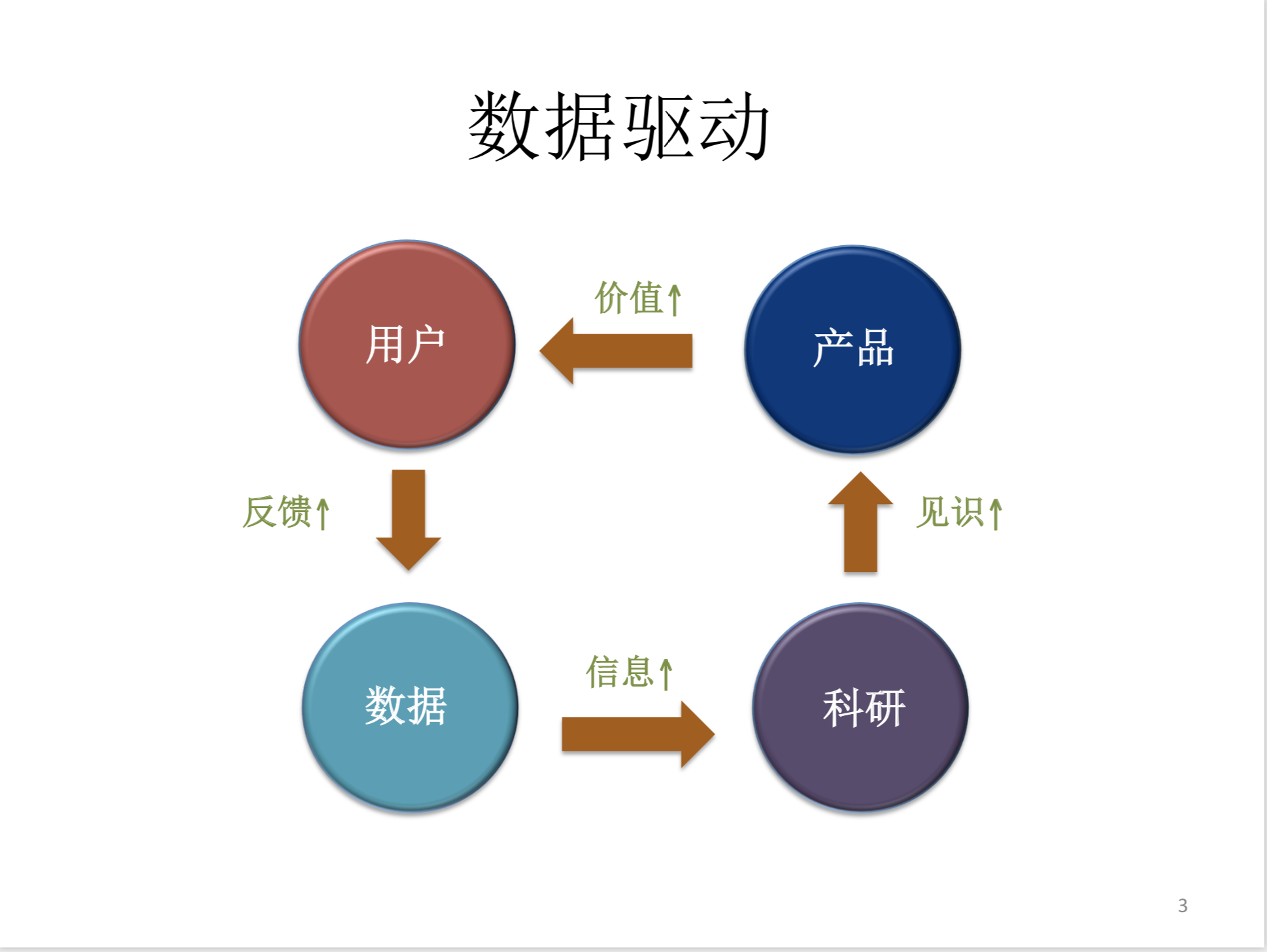
在领英的高速发展的过程中,之所以它能有这么高速发展与数据有不可分割的关系,领英像很多互联网公司一样,数据是它的核心,领英有自己的用户,通过自己提供的服务和用户交流,用户把自己的数据直接的或者间接地提供给领英,领英通过做各样的科研或者分析,可以提取出很多新的见识和认知,这些信息会被反馈到我们的产品上,这个产品就会做得更有效,可以吸引更多的用户到我们平台,所以如果数据做得好的话,可以形成一个非常好的良性循环,用户可以得到更多的数据,可以做更好的分析,可以生产更好的产品,又可以吸引到更多的用户。
数据源的多样性

从数据上角度来讲,领英的数据是非常多元化的,最常见的数据,可能大家都知道这是一种——交易数据,这些数据一般是存在数据库里的,从领英的角度来讲,这种这种交易数据就很简单,你提供工作简历,或者你上学的一些简历,包括你和里面成员的连接关系,都是一种交易性的数据,但是还存在大量的非交易数据,一些很多用户的行为数据,比如说作为一个用户,你点了哪个连接,你输入哪些搜索的关键词,这些其实都是非常有价值的信息。从我们内部的运营来讲,有很多的运营服务指标,一些应用程序的日志,然后到最后我们很多智能手机上的一些信息,这也非常有价值。所以从价值来讲,这些非交易性的数据的价值不亚于这些交易性数据的价值。但是从流量上来讲,这些非交易型的数据的流量可能是这种交易性数据的一百倍,甚至一千万倍的数据源。下面就举一个小的例子,看看领英怎么用这些数据的理念提供这个服务。
people you may know
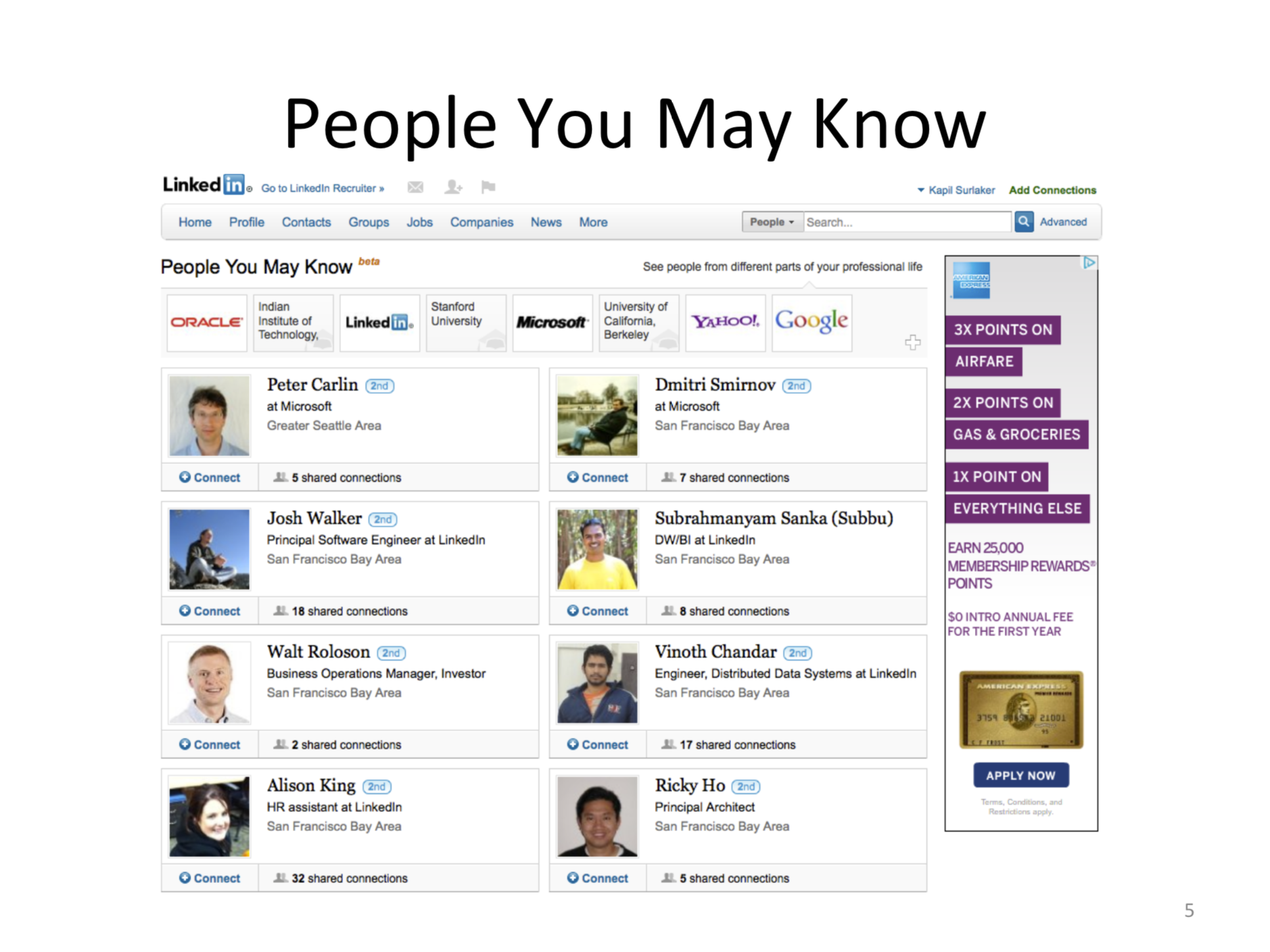
英文叫做people you may know,简称PYMK,这个机构做的事情就是提供给领英的用户一些推荐,他想推荐一些其他的领英的用户,目前还没有在你的连接里,他这个推荐是怎么做的呢?它内部里要用到30到40种信息,把这些信息加起来,使得给你最后一个推荐。举一些简单的例子,比如说我们两个人去过同一个学校,或者在一个公司工作过,这是一个很强的信息,也许我们就是需要连接在一起,但是有很这种非直接的信息,比如说甲和乙两个人,他们没有直接这种共同的一些明显的关系,但是如果在某一个很短的时间,有很多人同时看到这两个人的简历,那说明他们可能还有一些这种隐藏的信息,使得他们值得连在一起。所以在早期的领英,大家使用这个服务的话,就会发现很多的推荐非常神奇。你乍一看的话,可能觉得他怎么会推荐这么一个人给我,但是你如果细想一下,就会发现它有很多很强的理由,确实是有些道理,类似的在里面还有很多的服务,使得他可以用到各种各样的实时数据。但当时在2010年的时候,我们领英有很大的一块问题,就是在数据的集成上,其实是一个非常不完善的过程。这个图大概就介绍了一下当时的状态,所以在上面我看到这是各种各样的数据源,领英最开始是一个老牌的互联网公司,所有的数据都是存在数据库里头,随着理念的发展,我有一个系统是收集所有的用户行为的数据,很多的数据都是存在本地的文件里,还有一些其他的信息是存在运行上的日志里,运行一些识别监测数据。
在下游我们可以看到这是各种各样的消费端,领英最开始有这种数据仓库,随着时间的推移,我们有越来越多实时的微服务,它和这些批处理差不多,也要夺取或多或少同样的从这些不同数据源而来的信息。像我们刚才讲到的这种推荐引擎,它是其中的一个微服务,我们有很多这样的,还有一些社交的图形处理,他可以分析两个节点之间,比如两个领英的成员,他们之间是怎么连起来的,哪个连接是最强,还有一些实时的搜索,所以这些数量逐渐增多,而且他们很多的用法是更加的实时,从数据产生到它更新的系统,很多时候是几秒,甚至更短的一些延时。
点到点的数据集成
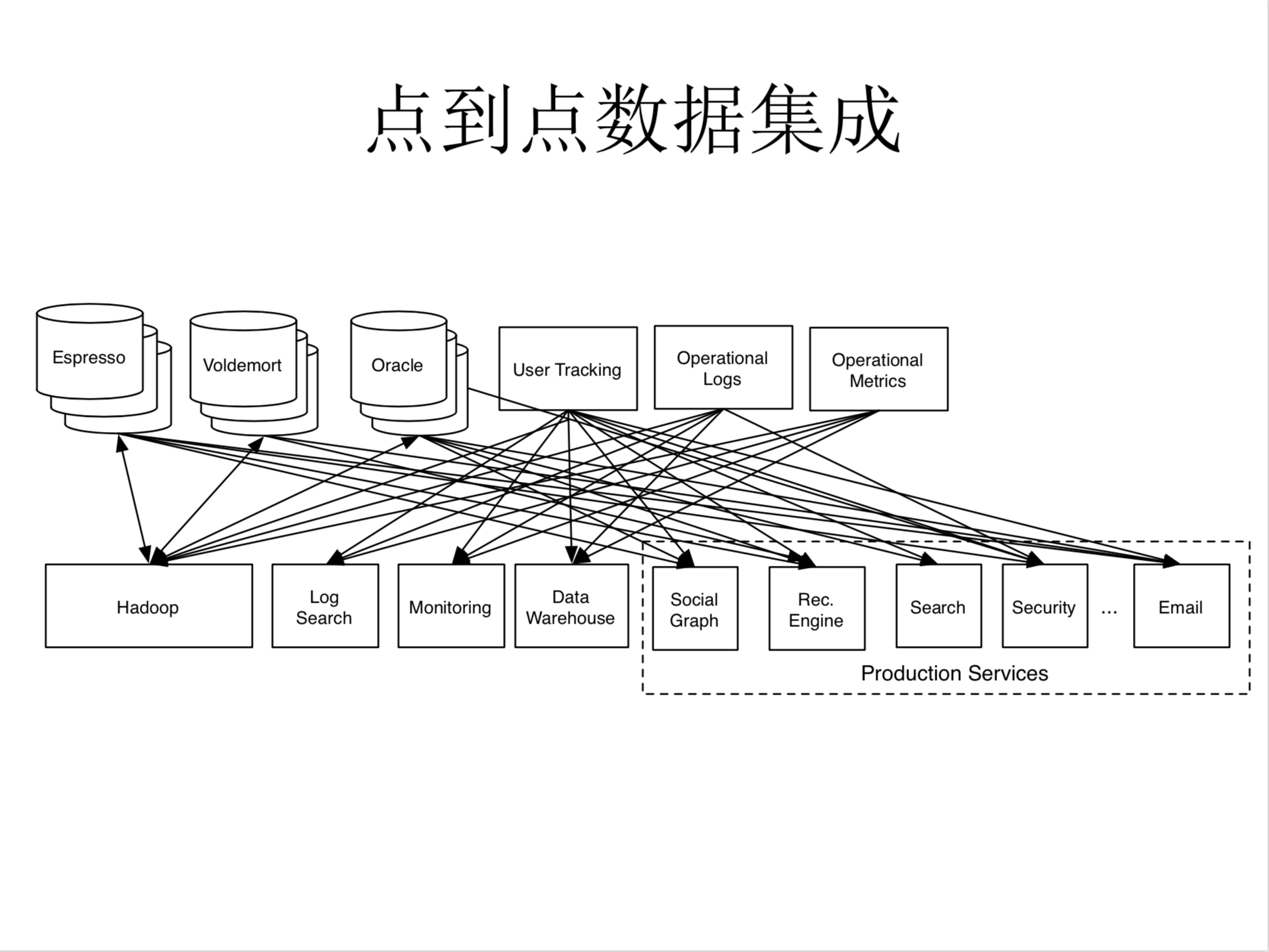
所以当时我们的做法是,如果想把这些数据送到从数据源送到消费端的话,做法就是我们说的点到点的数据集成,我们知道有些数据,我们想要的是把这些数据送到数据仓库里,我们的做法是写下脚本或者写一些程序。过了几天,我们发现很多系统里也需要读数据,我们又会做一些类似的工作,又在写下脚本一些程序,所以我们一直在很长一段时间都在做这种类似的东西,但是我写了五六个类似的数据流之后,发现这是一个非常低效的做法。主要的问题是什么?第一个我们要解决的问题是一个叉乘问题,是和数据员和数据消费端叉乘的问题。所以每增加一个数据源,就要把这个数据源和所有的消费端都连起来,同样增加一个消费端的话,消费端需要和所有的数据源直接连接。第二个问题就是我们在做这种点到点的流数据流的时候,每做一个数据流,我们都要重复很多相同的工作,另外每一个数据源,我们都没有足够的时间把它做到百分之百的尽善尽美,所以我们觉得这个体系结构不是非常理想。
理想架构
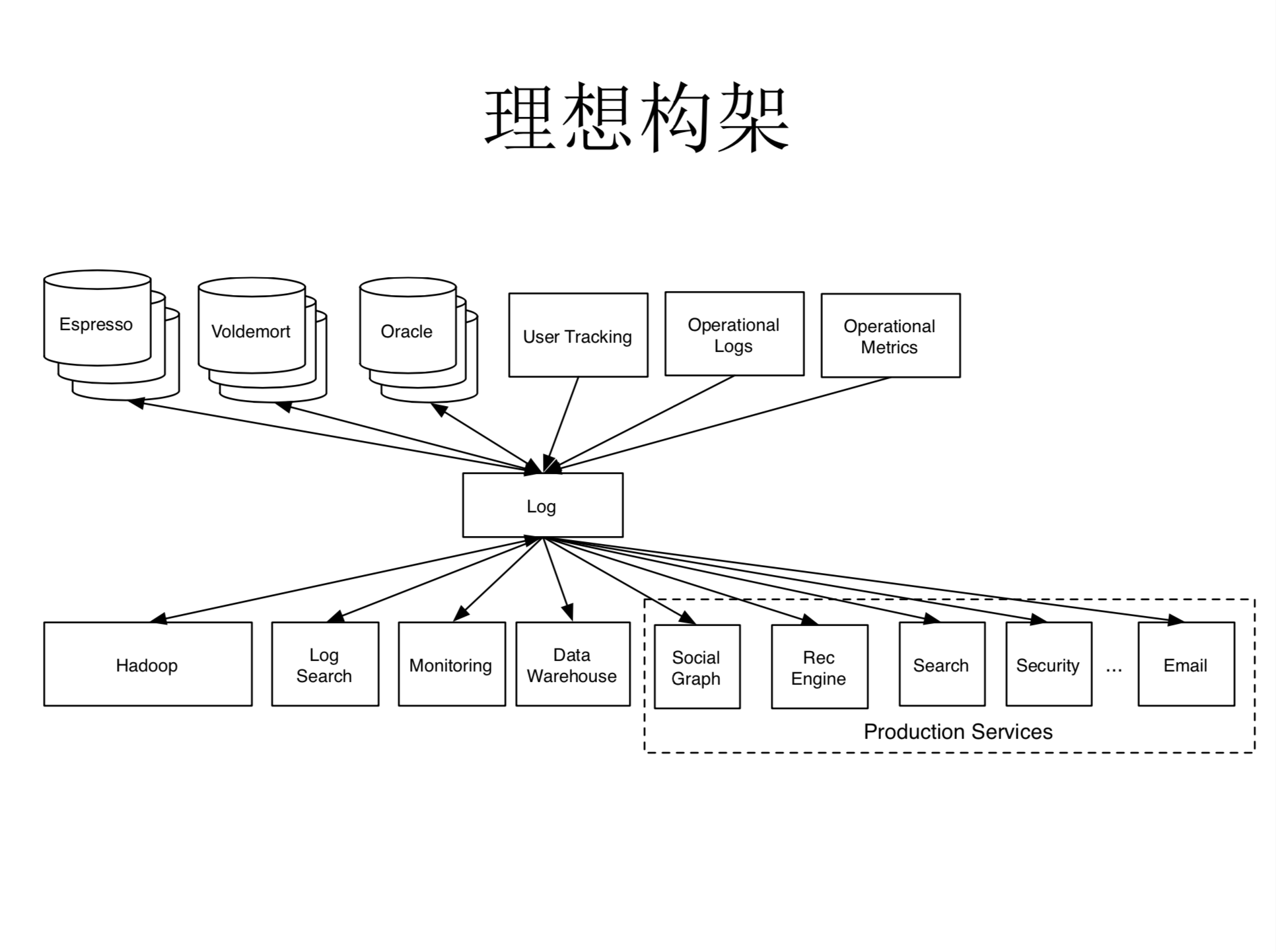
那么如果要改进的话,应该改进成什么样?我们当时想如果有这么一个体系结构,假设中间这个地方我们有一个集中式的日志系统,能够把所有数据源的信息先缓存住,如果能做到这一点,我们就会把这个框架大大的简化。所以你如果是数据源的话,你不需要知道所有的消费端,你唯一要做的事,就是把你的数据发送给中央的日志系统。同样你如果是一个消费端的话,你也不需要知道所有的数据源,你做的事情只是要像这种中央的日志系统去订阅你所要的消息,所以我们就把刚才叉乘问题简化成一个现实问题,关键的就是在体系结构里头,什么样的系统可以做这个中央的日志系统,所以这是我们当时在讨论的事情,我们最开始的话也没有想重新造一个新的系统,这个好像是一个非常常见的企业级的问题,那这个企业里应该有一个类似的解决方法。
首先尝试:不想重复造轮子

如果你仔细看一看,想一想,中央日志系统从界面角度来讲,类似于传统的消息系统。我们的消息系统一般把这种生产端和消费端分开,然后又是一个非常实时的系统,所以我们想为什么不尝试一些现有的消息系统,当时又有一些开源的消息系统,还有一些企业级的消息系统,但我们发现效果非常的不好。具体的原因有很多,但是最重要的一个原因就是这些传统的消息系统,从它的设计上来讲,不是给我们这个用法来设计的,尤其最大的问题就是它的吞吐量。
Kafka第一版:高吞吐发布订阅消息系统

很多的这种早期的消息,他的设计师给这些数据库上的数据,这种消费交易型数据来设计,但是你可能很难想象把很多非交易性数据,比如说用户行为日志,还有一些这种监测数据,都通过这种传统的消息来流通。所以在这种情况下,我们觉得我们没有办法解决这个问题,但又没有一个现成的结果,那么就说我们自己来做一个事情。在2010年左右,我们做了开始做kafka的第一个版本。第一个版本我们的定位也很简单,就想把它做成一个高吞吐的消息系统,高存储是我们最重要的目的。
分布式架构
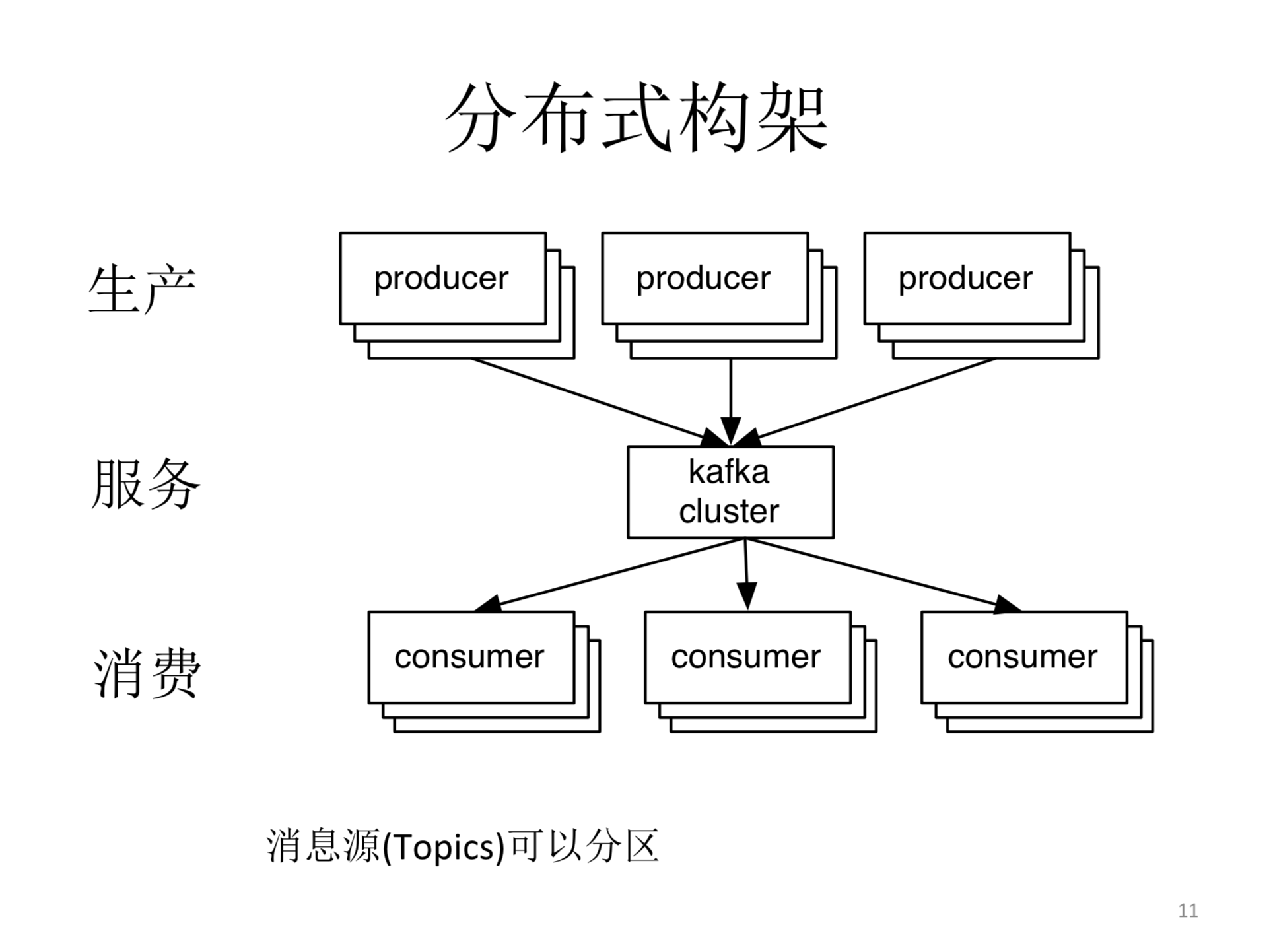
下面的话,我们大概讲讲我们怎么实现高吞吐。第一件事我们做了高吞吐,就是把在咖啡的第一个版本里,我们就把它做成一个分布式的框架。很多熟悉kafka的人都知道,kafka里面有三层,中间这层加服务层下面是生产端,然后下面是消费端。服务端的话一般有一个或者多个节点,基本的概念叫做消息拓片,这个消息源是可以分区的,每一个分区可以放到某一个节点的某一个硬盘上,所以如果想增加吞吐的话,最简单的方法就是增加集群里的机器,可以有更多的资源,不管是从存储还是带宽的角度,你都可以有更多的资源来接受很多的数据,同样我们生产端和消费端做的也是一个这种多线程的设计。在任何一个情况下,你可以有成千上万的这种生产端的线程和消费端的线程,从喀斯特机群上写或者读取数据。所以这个设计就是说在我们第一个班级有的东西很多,这种老牌的一些消息系统。
简单实用的日志存储
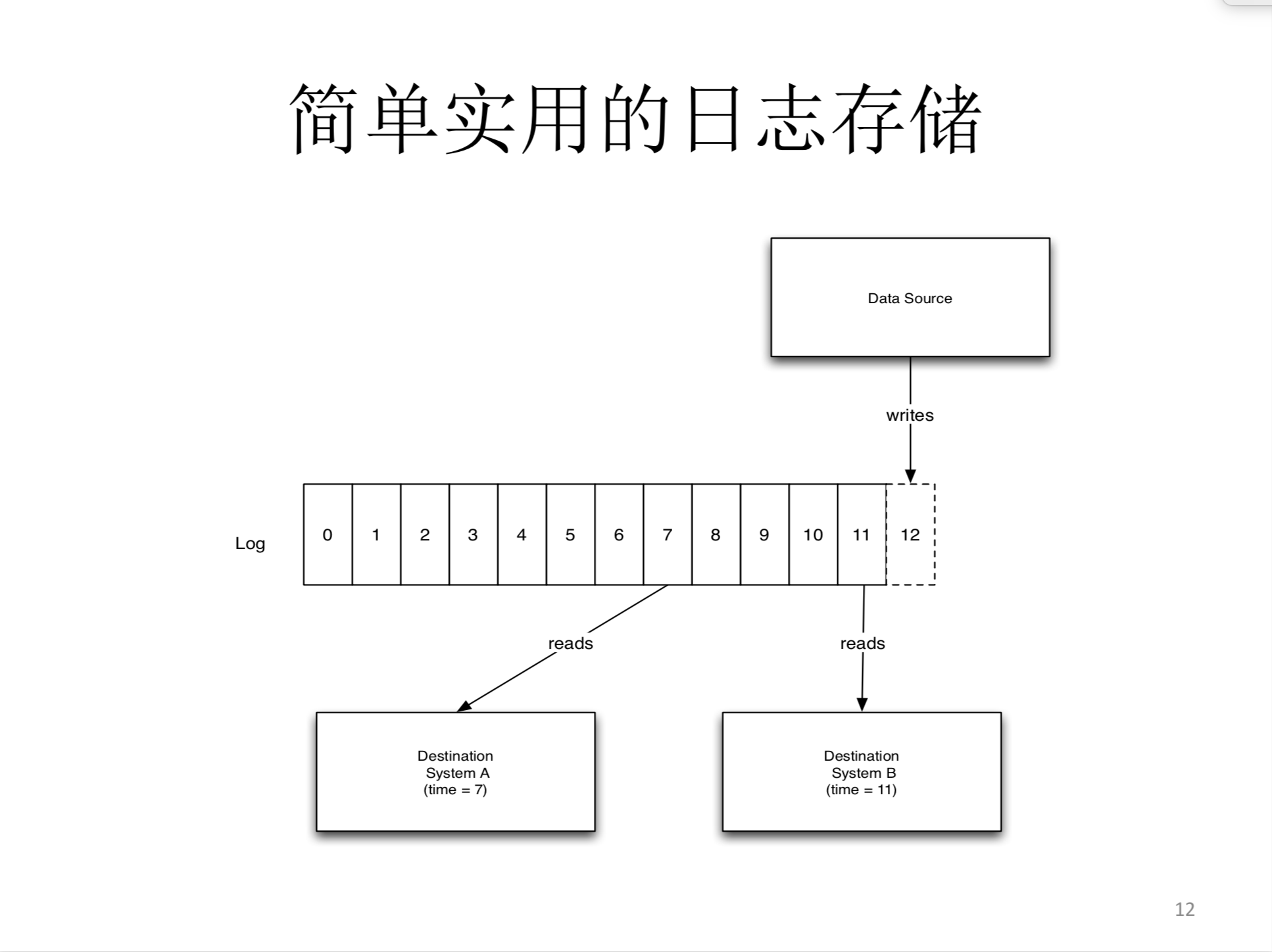
第二点我们做的是使用了一个日志的存储结构,这个也非常简单,但是它是一个非常有效的存储结构,所以大概是它的一些结构的话是每一个消息源的分区,都会有一个相对应的这么一个日志结构,而且日志结构式和硬盘挂在一起的所有会是通过硬盘来存储的。这个结构里面就是每一个小方块都对应了一个消息,每一个消息有一个代号,代号是连续增加的,如果你是一个生产端的话,你做的事情就是你把你要写的消息写到日志的最后面,你会得到一个新的更大的消息代号日志,再送到给消费端的话是按顺序送的,你按什么顺序写进去,他就按什么顺序送给消费端,这样的好处是,从消费端来讲你的开销非常的小,因为不需要记住所有消费端的消息,只需要记住它最后消费过的一个消息的代号。然后记住这个的话,它就可以从这个地方往后继续消费,因为我们知道所有的消息都是按顺序去做发送的,所以在这个消息之前的所有消息应该已经全都被消费过了。
两个优化

这个设计有几个好处,第一个好处就是他的访问的模式非常利于优化,因为不光是从写的角度还是从读的角度来讲,这个都是线性的写,读也是从某一个位置开始线性的读。所以从这个角度出发,利于操作系统和文件系统来优化它的性能。第二点,我们这个系统设置上可以支持同时多消费,在任何时候你可以有一个或者多个消费者,消费者他可以说从这个地方开始消费,另一个消费者可以从一个不同的地方再消费,但不管你有多少个消费者,这个数据只是存一次,所以从存储的角度来讲,它的性能和你消费的次数是没有关系的。另外一点并不是很明显的,由于我们日志是存在硬盘上的,使得我们可以同时接收实时的消费者,也可以接受一些不实时的批处理的消费者。但是因为所有的数据都在硬盘上,我们可以有一个非常大的缓存,所以不管你是实时还是不实时的,从消费者端的服务方法都是一套的,他不需要做不同的优化,唯一的就是我们依赖这种操作系统来决定哪些数据是可以从内存里提供给消费者,哪些需要从硬盘里来读。但是从这个框架的设计上都是一样的。最后一点我们做成这种高吞吐,我们又做了两个小的优化,这两个优化是有关联的,第一个优化就是批处理,所有三个层面在服务端,刚才我们说到这些消息是要存在一个基于硬盘的日志里,但是写到硬盘的话它是有一定的开销,所以我们不是每一个消息就马上写了这个硬盘,而是一般会等一段时间,当我们积攒了一些足够的消息之后,才把他一批写到硬盘,所以虽然你还有同样的开销,但你这个开销是分摊到很多消息上,同样在生产端也是这样,如果你想发送一个消息,我们一般也不是马上就把这个消息作为一个远程的请求发送给这个服务端,而是我们也会等一等,希望能够等到一些更多的消息,把他们一起打包送到这个服务端。和批处理相关的就是数据压缩,我们压缩也是在一批数据上进行压缩,而且是从端到端的压缩,如果你开启压缩的功能的话,再生产端我们先会等一批数据等到一批数据完成之后,我们会把这一批数据一起做一个压缩,击压缩一批数据,往往会得到比这个压缩每一个消息得到更好的压缩比例也是。不同的消息往往会有一些这种重复,然后压缩的数据会被从生产端送到这个服务端,那服务端会把数据压缩的格式存在日志里头在以压缩的格式送到消费端,直到消费端在消费一个消息的时候,我们才会把这个消息解压。所以如果你启动了压缩的话,我们不光节省了网络的开销,还节省了这个寄存开销,所以这两个都是非常有效的实现这种高吞吐的方法。所以我们第一个版本kafka做了大概有半年左右的时间,但是我们又花了更多的一点时间把它用到领英的数据线上,因为领英内部有很多的微服务,大概在我们2011年底的时候做完了这件事,这是当时的一些基本的数量。
kafka在领英2011

生产端我们当时有几十万的消息被生产出来,然后有上百万的消息被消费,这个数据在当时还是非常的可观,而且领英当时有几百个微服务,上万个微服务的线程,更重要的是我们在做了这个事情之后,实现了这个领域内部的一个数据的民主化。在没有kafka之前,你如果是领英的一个工程师或者是一个产品经理,或者是一个数据分析家,你想做一些新的设计或者新的这种应用程序,最困难的问题是你不知道应该用什么样的界面去读取,也不知道这个数据是不是完整。做了kafka这件事情,我们就把这一块的问题大大的简化了,大大解放了工程师创新的能力。所以有了成功的经历,并且感觉kafka的这个系统非常有用,我们又往后做了一些更多的开发,第二部分的开发主要是做一些这种高可用性上的支持。
Kafka第二版:高可用性
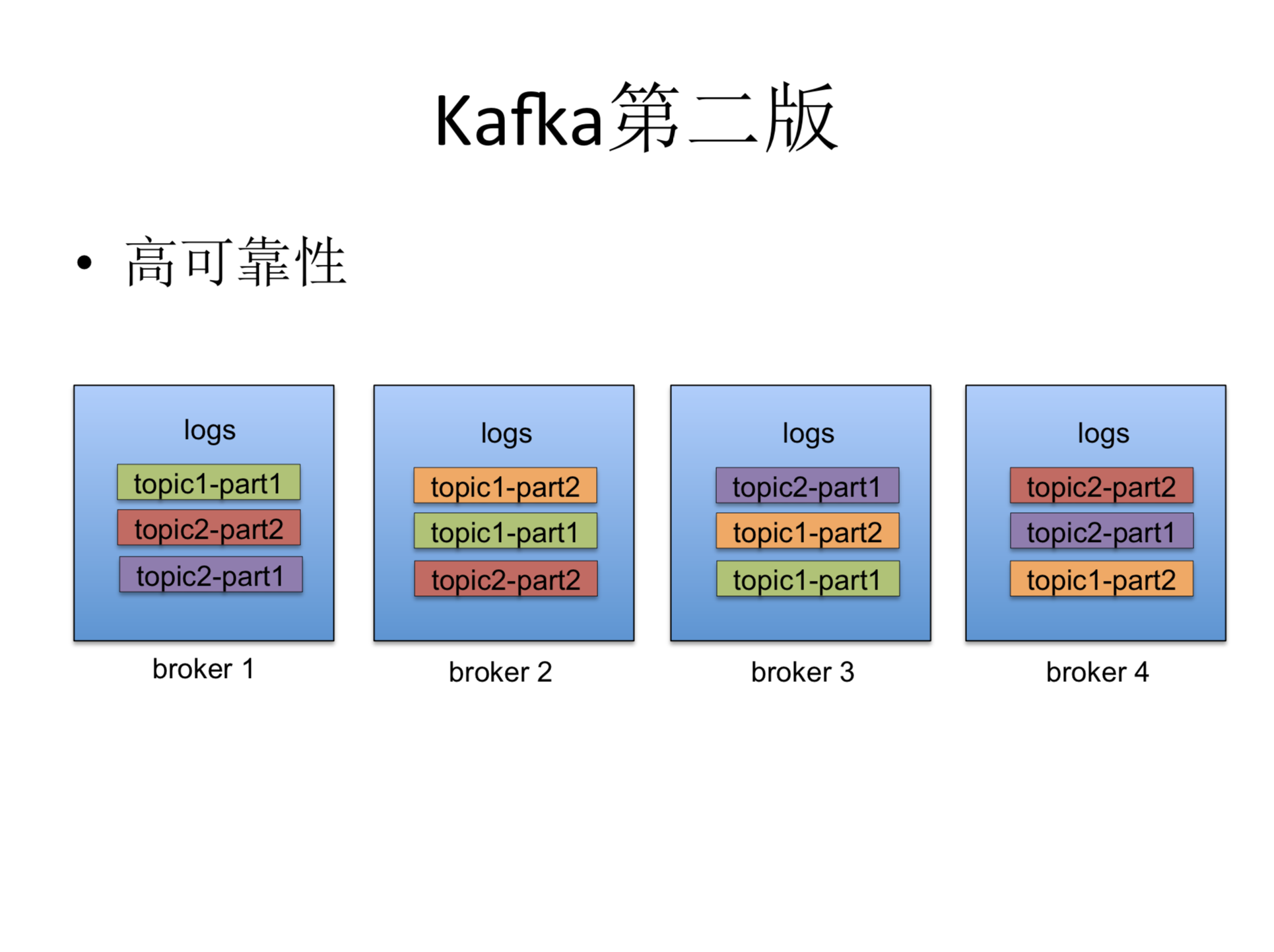
第一个版本里的话,每一个消息只是被存在一个节点上,如果那个节点下机的话,那这个数据就没法获取了。如果这个机器是永久性的损坏的话,你的数据还会丢失。所以第二版我们做的时候,就是增加了一些这种高可用性,实现方法就是增加的这种多副本的机制。如果群里有多个节点的话,那我们可以把一个消息冗余的存在多个副本上,同一个小的颜色是多个不同的副本。在同样的情况,如果你一个机器下线的话,另外一个迹象,如果还有同样的副本,他还可以继续持续提供同样数据的服务。所以有了第二个版本之后,我们就可以把它可能够包括的数据的面能够拓展得更广一点,不光是这种非交易性的时候,一些包括交易性的数据,也可以通过我们的系统来被收集。
Kafka于2011年加入Apache
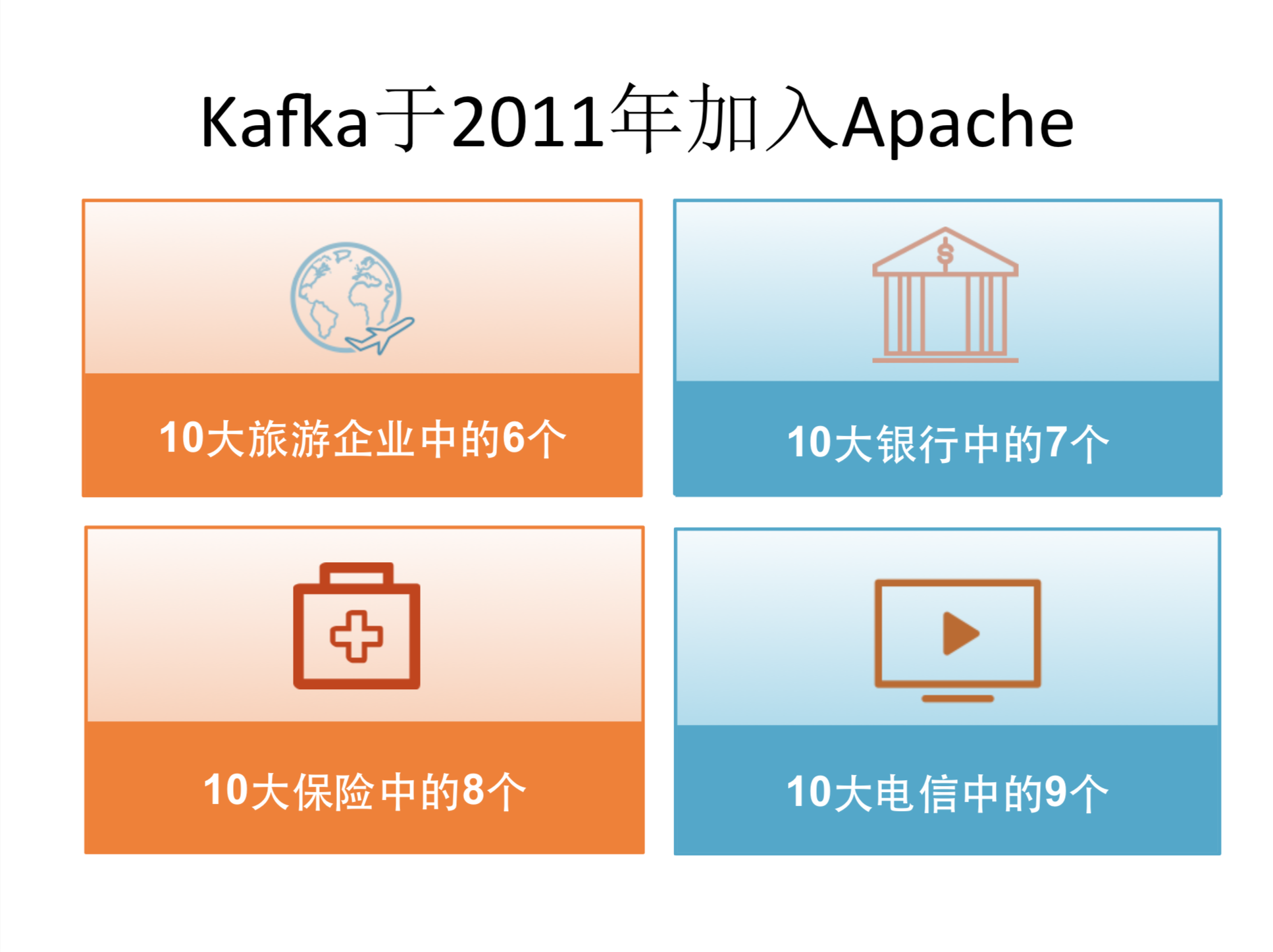
在2000年我们还做了一件事,那一年是kafka这个项目被捐赠给了阿帕奇基金会,当时我们做这个事也是觉得我们做的系统至少对领域内部非常有用,那我们就看看是不是对其他的公司也有一些用处,其他的互联网公司也许也觉得有用,但是我没有意识到开源了之后,他用途是非常广泛,所以往往是布局网,不只是局限于这种互联网的公司而是整个工业界。只要你的公司有些这种实时数据,你需要收集的话都可以用得上。很大的原因是一些各种各样的传统的企业,它也在经历这种软件化数字化的过程。有一些传统行业,以前强的地方可能是在那些传统的制造业,或者说有一些零售点,但现在必须在软件上或在数据上也能够比较强才可以。那kafka就从实时这种数据的集成上,给很多企业都提供了非常有效的渠道。
Confluent于2014年成立

在下一步我们经历了几年kafka的开发,知道它用途越来越广,所以我们就想做一件致力于kafka上的事,因为这个事是全职性的工作,所以我们在2014年就离开了领英成立了Confluent公司。这个公司我们是想为各种各样的企业提供方便,用的可以更广一点,现在我们的公司大概是有超过两百人。
Kafka的发展

下面大概讲一讲从14年之后我们做了哪些发展。在这之后,kafka我们主要做了两块的东西,第一块和企业级的功能有关的东西,这块主要是和数据集成有关的。第二块是和数据流处理有关的。那么两方面都会稍微讲一讲。这个就跳过去了,在企业界上我们做了很大的一块,和刚才我们最开始讲的数据集成的事情有关。很多的这种公司,如果你的公司时间比较长的话,你会发现你数据源是分散在很多的系统里,刚才我们讲的就是有kafka之后很方便,你可以把这些数据提取出来,但是不同的公司的话,你不希望每个公司都读东西来做他们自己的一套东西,所以我们设计的初衷中有两块,第一块是它有一个平台部分,里面它把很多常见的东西提取出来,做成一个模块,比如说你需要做一些数据的分布,你需要做一些并行处理,你还需要做一些这种失败检测,检测之后你能再做一些数据平衡,所以这些常见的东西都做到这个模块里面,这个模块里面又有一个开放式的接口,这个接口可以用来设计实现各种各样的不同的数据源的连接。在数据的发送端的地方,如果想搜索一些副本,我们也可以做一些类似的事情,所以这是我们做的第一块。
第二块做的就是和数据流有关的一个方面。如果你有一个系统,像kafka里能实时把很多的数据收集起来,最开始的用途是当成一个数据传输的平台。但是我们觉得加以时间的话,kafka可能并不只局限一个传输平台,而且还可以做这种分享合作的平台,有实时数据之后,你常做的一些事情比如说你要做一些这种数据流的出来,比如说把一个数据从一个格式转到另外一个格式,你可能还想做一些数据的扩充,比如说你有一个数据流,里面有一些数据的信息,但只有用户的代号,没有数据的用户的具体信息,但是你有一个可能数据库里有很多更详细的用户的信息,如果您能够把这两个信息并在一起,这个数据流就更丰富,可以使你做一些更多的更有效的处理。另外你可能也想做一些实时的数据的聚合,应用程序里,我们想把这一块再简化。
数据安全

Kafka connect
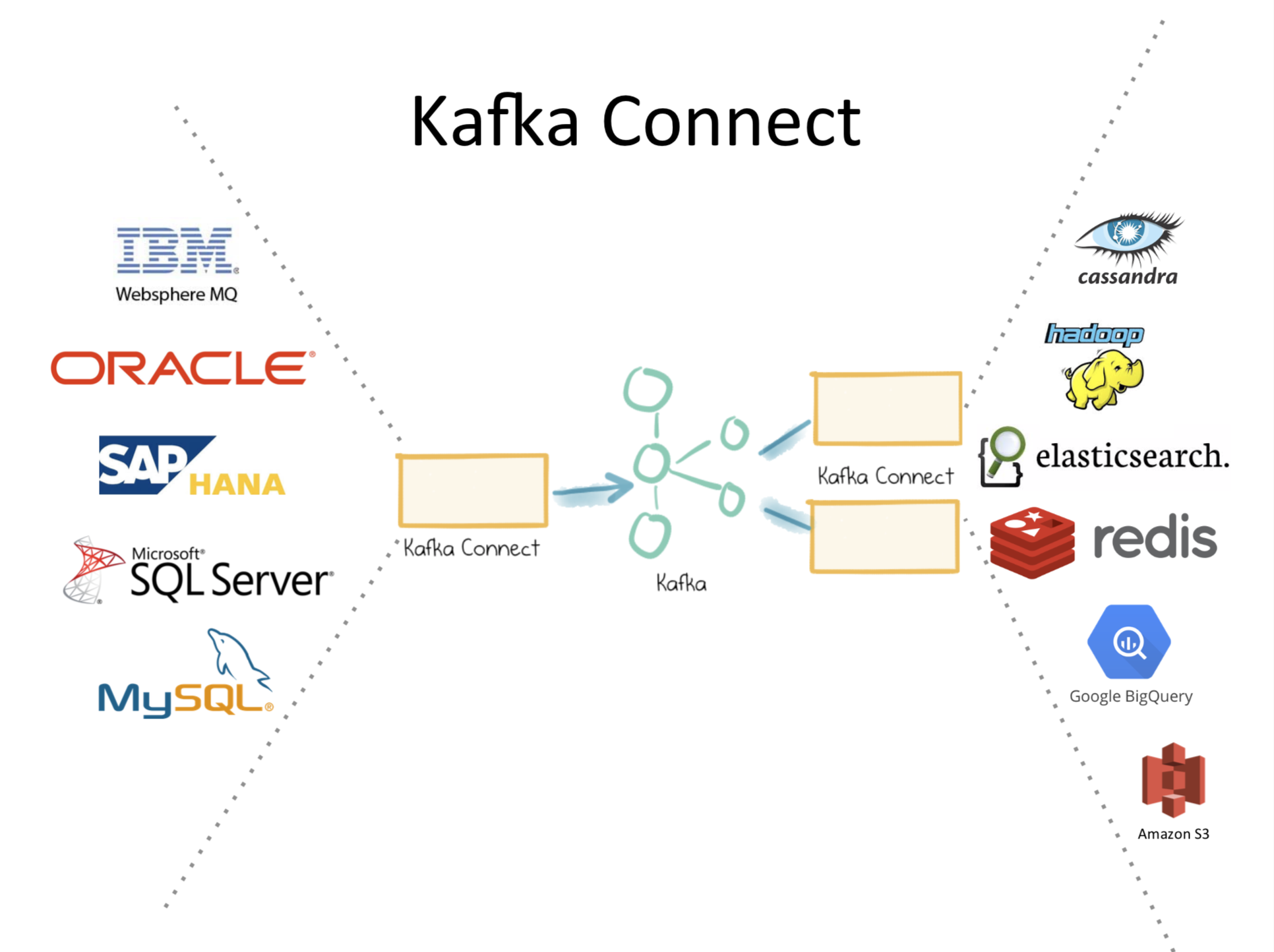
数据流处理

Kafka Streams

KSQL

Kafka的未来
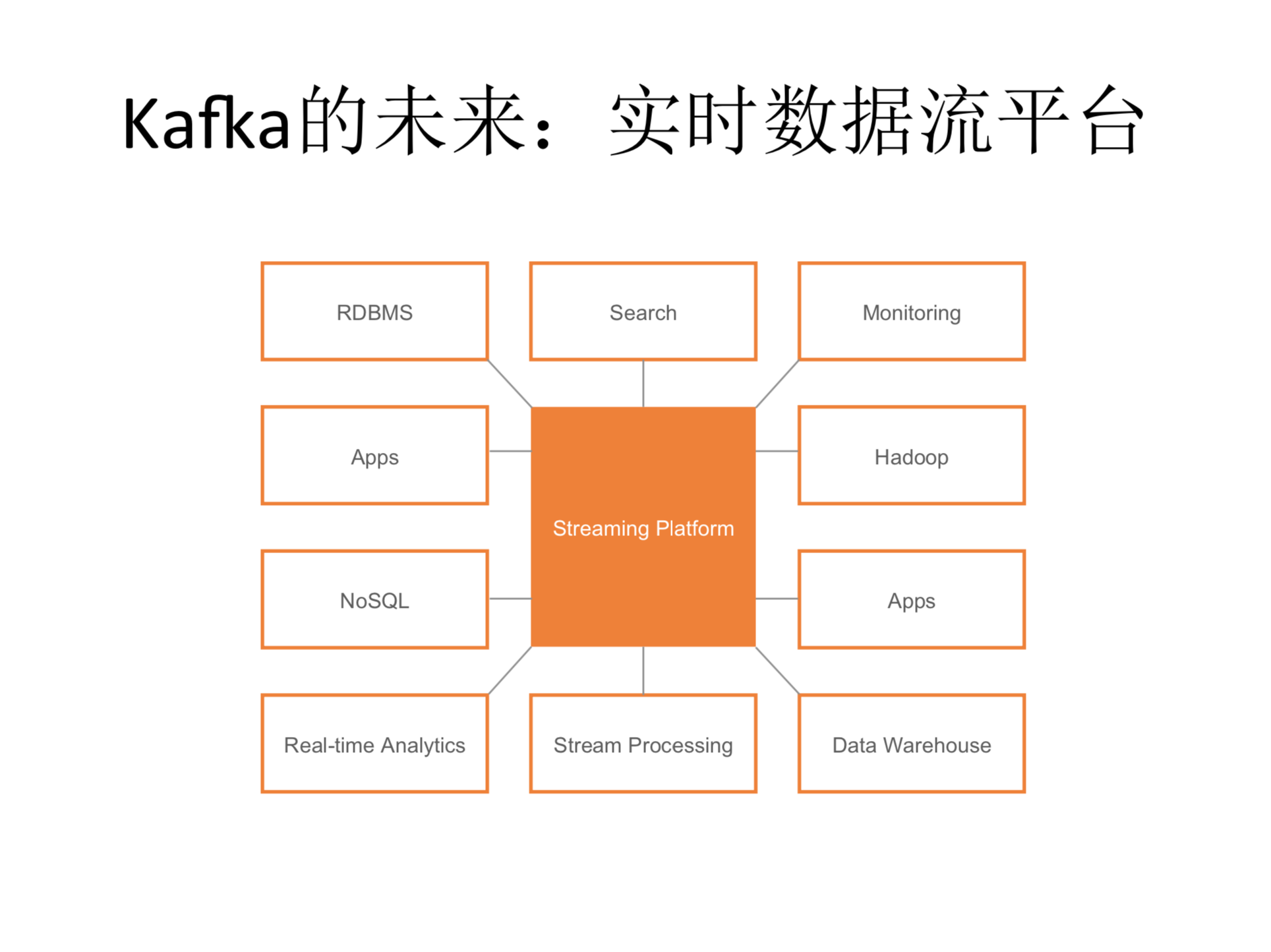
未来的话,我觉得kafka系统不光是一个实时的数据收集和传输的平台,更多的可能随着时间发展的话,它可能还是更多的数据流的处理,交换和共享的一个平台,所以我们会在这个方向上做更多的东西。未来随着很多的应用更广,我们觉得很多的应用程序会越来越变成这种实时的应用程序。所以在这个基础上,我们在kafka上可能会有很强的一套生态系统。
结尾

最后给大家分享一个小的故事。这个故事是是我们北美的一个用户,这个银行是一个比较传统的老牌银行,已经是几十年的一个历史银行,很长时间存在的一个问题是它的数据是非常的分分散的。所以你如果是这个银行的客户,你可能有一个银行的账户,你可能有一个贷款,你可能还有一个保险,你可能还有一张信用卡,以前所有这个客户的信息,因为它都是不同的商业部门,它都是完全分开的。你如果作为一个银行的销售人员,你苦恼的事就是没法知道这个客户的所有的信息。这个公司它做了一个和Kafka有关的项目,一个项目就是把所有的客户的不同的数据源信息都实时地收集起来,然后把这个信息推提供给他们上万个销售人员,这样的话销售人员在做销售的时候,就会有更有效的一些实时信息可以给客户做一些更有针对的推荐,所以这个项目就非常成功。