我们在使用 Apache Kafka 生产和消费消息的时候,肯定是希望能够将数据均匀地分配到所有服务器上。比如很多公司使用 Kafka 收集应用服务器的日志数据,这种数据都是很多的,特别是对于那种大批量机器组成的集群环境,每分钟产生的日志量都能以 GB 数,因此如何将这么大的数据量均匀地分配到 Kafka 的各个 Broker 上,就成为一个非常重要的问题。那么 Kafka 生产者如何实现这个需求呢。
为什么分区(partition)?
对于每一个主题(topic), kafka集群都会维持一个分区日志,如下所示:
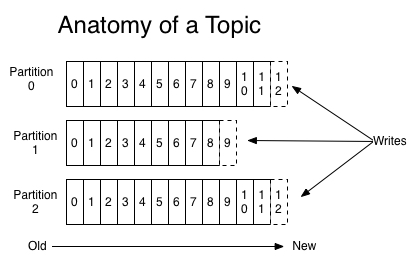
每个分区都是有序且顺序不可变的消息记录集,消息被不断地追加到commit log文件末尾。主题下的每条消息只会保存在某一个分区中。kafka为什么要分区呢?分区主要有以下几个原因:
第一,当日志大小超过了单台服务器的限制,允许日志进行扩展。每个单独的分区都必须受限于主机的文件限制,不过一个主题可能有多个分区,因此可以处理无限量的数据。
第二,提供负载均衡的能力。不同的分区分布在Kafka集群不同的节点服务器上。每个服务器在处理数据和请求时,共享这些分区。每一个分区都会在已配置的服务器上进行备份,确保容错性。每个分区都有一台 server 作为leader,零台或者多台server作为follwers 。leader server 处理一切对分区的读写请求,而follwers只需被动的同步leader上的数据。当leader宕机了,followers 中的一台服务器会自动成为新的 leader。每台 server 都会成为某些分区的 leader 和某些分区的 follower,因此集群的负载是平衡的。并且,我们还可以通过添加新的节点机器来增加整体系统的吞吐量。
第三,除了提供负载均衡这种最核心的功能之外,利用分区也可以实现其他一些业务级别的需求,例如,如果使用用户ID作为key,则用户相关的所有数据都会被分发到同一个分区上。 这允许消费者在消费数据时做一些特定的本地化处理。
分区策略
所谓分区策略是决定生产者将消息发送到哪个分区的算法。Kafka 为我们提供了默认的分区策略,同时它也支持你自定义分区策略。
Partitioner接口
这个接口很简单,只定义了两个方法:partition()和close(),通常你只需要实现最重要的 partition 方法。我们来看看这个方法的方法签名:
1 | int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster); |
这里的topic、key、keyBytes、value和valueBytes都属于消息数据,cluster则是集群信息(可以获得一个主题的所有分区信息列表和available分区信息列表等等)。我们能够充分地利用这些信息对消息进行分区,计算出它要被发送到哪个分区中。只要你自己的实现类定义好了 partition 方法,同时设partitioner.class参数为你自己实现类的 Full Qualified Name,那么生产者程序就会按照你的代码逻辑对消息进行分区。
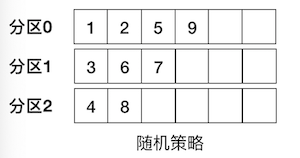
随机策略
也称 Randomness 策略。所谓随机就是我们随意地将消息放置到任意一个分区上,如下面这张图所示。
如果要实现随机策略版的 partition 方法,很简单,只需要两行代码即可:
1 | List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); |
先计算出该主题总的分区数,然后随机地返回一个小于它的正整数。
本质上看随机策略是力求将数据均匀地打散到各个分区,但从实际表现来看,它要逊于下面介绍的轮询策略,目前已经弃用。
轮询策略
RoundRobinPartitioner,也称 Round-robin 策略,即顺序分配。比如一个主题下有 3 个分区,那么第一条消息被发送到分区 0,第二条被发送到分区 1,第三条被发送到分区 2,以此类推。当生产第 4 条消息时又会重新开始,即将其分配到分区 0,就像下面这张图展示的那样。
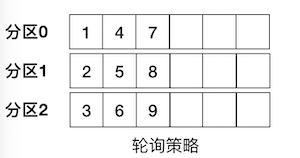
这就是所谓的轮询策略。轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上。但是在吞吐量较小的情况下,也会导致更多批次,而这些批次的大小更小,其实,将所有记录转到指定的分区(或几个分区)并以更大的批记录一起发送似乎会更好。在key=null时,轮询策略是2.3版本默认使用的分区策略,2.4版本(KIP-480)引入了更好的黏性分区策略。
黏性分区策略
UniformStickyPartitioner,黏性分区策略。
消息记录会成批的从生产者发送到Broker。生产者触发发送请求的时机由批记录的大小参数和linger.ms参数决定,批记录的大小达到设定的值或linger.ms参数时间到,都会触发批记录的发送。因此,批记录的大小对生产者到Broker发送延迟是有影响的。较小的批记录会导致更多的请求和排队从而导致更高的延迟。这意味着,在关闭linger.ms的情况下(即将linger.ms参数设置为零),较大的批记录也会减少延迟。在启用linger.ms的情况下,低吞吐量通常会向系统中注入延迟,因为如果没有足够的记录来填充批记录,则需要等到linger.ms设定的参数值才会发送该批记录。在linger.ms值之前找到增加批记录大小以触发发送的方法将进一步减少延迟。
黏性分区策略通过“黏贴”到分区直到批记录已满(或在linger.ms启动时发送),与轮询策略相比,我们可以创建更大的批记录并减少系统中的延迟。即使在linger.ms为零立即发送的情况下,也可以看到改进的批处理和减少的延迟。在创建新批处理时更改粘性分区,随着时间的流逝,记录应该在所有分区之间是平均分配的。2.4版本key=null时默认使用黏性分区策略
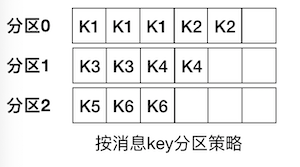
按消息key分区策略
Kafka 允许为每条消息定义消息键,简称为 Key。这个 Key 的作用非常大,它可以是一个有着明确业务含义的字符串,比如客户代码、部门编号或是业务 ID 等;也可以用来表征消息元数据。特别是在 Kafka 不支持时间戳的年代,在一些场景中,工程师们都是直接将消息创建时间封装进 Key 里面的。一旦消息被定义了 Key,那么你就可以保证同一个 Key 的所有消息都进入到相同的分区里面,如下图所示。
自定义分区策略
一种比较常见的,即所谓的基于地理位置的分区策略。当然这种策略一般只针对那些大规模的 Kafka 集群,特别是跨城市、跨国家甚至是跨大洲的集群。
我就拿“美团app”举个例子吧,假设美团app的所有服务都部署在北京的一个机房(这里我假设它是自建机房,不考虑公有云方案。其实即使是公有云,实现逻辑也差不多),现在美团app考虑在南方找个城市(比如广州)再创建一个机房;另外从两个机房中选取一部分机器共同组成一个大的 Kafka 集群。显然,这个集群中必然有一部分机器在北京,另外一部分机器在广州。
假设美团app计划为每个新注册用户提供一份注册礼品,比如南方的用户注册极客时间可以免费得到一碗“甜豆腐脑”,而北方的新注册用户可以得到一碗“咸豆腐脑”。如果用 Kafka 来实现则很简单,只需要创建一个双分区的主题,然后再创建两个消费者程序分别处理南北方注册用户逻辑即可。
但问题是你需要把南北方注册用户的注册消息正确地发送到位于南北方的不同机房中,因为处理这些消息的消费者程序只可能在某一个机房中启动着。换句话说,送甜豆腐脑的消费者程序只在广州机房启动着,而送咸豆腐脑的程序只在北京的机房中,如果你向广州机房中的 Broker 发送北方注册用户的消息,那么这个用户将无法得到礼品!
此时我们就可以根据 Broker 所在的 IP 地址实现定制化的分区策略。比如下面这段代码:
1 | List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); |
我们可以从所有分区中找出那些 Leader 副本在南方的所有分区,然后随机挑选一个进行消息发送。
DefaultPartitioner默认分区策略
key不为null时,对key进行hash(基于murmurHash2算法),根据最终得到的hash值计算分区号,有相同key的消息会被写入同样的分区;key为null时,2.3版本使用轮询分区策略,2.4版本使用黏性分区策略。
生产者分区逻辑
指定partition的情况下,直接发往该分区;没有指定partition的情况下,根据分区策略确定发往的分区。配置了自定义分区策略的情况下使用自定义的分区策略,没有配置的情况下使用默认分区策略DefaultPartitioner。
小结
分区是实现负载均衡以及高吞吐量的关键,故在生产者这一端就要仔细盘算合适的分区策略,避免造成消息数据的“倾斜”,使得某些分区成为性能瓶颈,这样极易引发下游数据消费的性能下降。
Kafka的消息组织方式实际上是三级结构:主题-分区-消息。主题下的每个消息只会保存在某一个分区中
为什么要分区
- 无限存储
- 负载均衡
- 特定业务保序需求
分区策略:是决定生产者将消息发送到那个分区的算法
- 随机分区策略-randomness
- 轮询分区策略-round-robin
- 黏性分区策略-sticky partitioner
- 按消息键分区策略
- 自定义,比如:基于地理位置的分区策略
- 默认分区策略DefaultPartitioner:key不为null时,对key进行hash(基于murmurHash2算法),根据最终得到的hash值计算分区号,有相同key的消息会被写入同样的分区;key为null时,2.3版本使用轮询分区策略,2.4版本使用黏性分区策略。
生产者分区逻辑:指定partition的情况下,直接发往该分区;没有指定partition的情况下,根据分区策略确定发往的分区。配置了自定义分区策略的情况下使用自定义的分区策略,没有配置的情况下使用默认分区策略DefaultPartitioner。
附录
KIP-480:黏性分区策略(Sticky Partitioner)
动机
消息记录会成批的从生产者发送到Broker。生产者触发发送批记录(record batches)请求时机由批记录的大小参数和linger.ms参数决定,批记录的大小达到设定的值或linger.ms参数时间到,都会触发批记录的发送。因此,批记录的大小对生产者到Broker发送延迟是有影响的。较小的批记录会导致更多的请求和排队从而导致更高的延迟。这意味着,在关闭linger.ms的情况下(即将linger.ms参数设置为零),较大的批记录也会减少延迟。在启用linger.ms的情况下,低吞吐量通常会向系统中注入延迟,因为如果没有足够的记录来填充批记录,则需要等到linger.ms设定的参数值才会发送该批记录。在linger.ms值之前找到增加批记录大小以触发发送的方法将进一步减少延迟。
当前(2.3版本),在未指定分区(partition)且未指定key的情况下,默认分区器(DefaultPartitioner)将以循环方式对记录进行分区。这意味着一系列连续记录中的每个记录将被顺序发送到每一个分区,直到我们用尽分区再重新开始。尽管这会在各个分区之间平均分配记录,但也会导致更多批次,而这些批次的大小更小。将所有记录转到指定的分区(或几个分区)并以更大的批记录一起发送似乎会更好。
黏性分区器尝试在分区器中创建类似行为。通过“黏贴”到分区直到批记录已满(或在linger.ms启动时发送),与默认分区器相比,我们可以创建更大的批记录并减少系统中的延迟。即使在linger.ms为零我们立即发送的情况下,我们也可以看到改进的批处理和减少的延迟。发送批记录后,黏性分区会更改。随着时间的流逝,记录应该在所有分区之间是平均分配的。
Netflix有一个类似的想法,并创建了一个黏性分区器,该分区器选择一个分区并在给定的时间段内将所有记录发送到该分区,然后再切换到新分区。
另一种方法是在创建新批处理时更改粘性分区。这样做的目的是最大程度地减少可能在不合时宜的分区交换时机上参生更多的空批记录。我们介绍的黏性分区器将使用这个方法。
Partitioner接口
粘性分区将是默认分区器的一部分,因此不会直接有公共接口。
Partiton接口增加一个新的Public方法。
1 | /** |
onNewBatch方法将在创建新批记录之前立即执行代码。 粘性分区程序将定义此方法来更新粘性分区。 这包括更改粘性分区,即使键值上将有新批次也是如此。 测试结果表明,在键值情况下,此更改不会显著影响延迟。
此方法的默认设置将不会更改当前用户定义的其他分区器的分区行为。 如果用户想在自己的分区器中实现粘性分区,则可以重写此方法。
拟议的变更
- 在无显式分区(key = null)的情况下更改默认分区器的行为。 选择给定Topic的“粘性”分区。 当记录累加器为给定分区上的主题分配新批次时,“粘性”分区将更改。
- 这些更改也会略微修改具有键的记录的代码路径,但是这些更改不会显着影响延迟。
- 将创建一个名为UniformStickyPartitioner的新分区器,以允许对所有记录进行粘性分区,即使是那些具有非空键的记录也是如此。 这将镜像到RoundRobinPartitioner如何对所有记录(包括具有键的记录)使用循环分区策略。
兼容性,弃用和迁移计划
- 无需兼容处理,无需弃用,无需迁移计划。
- 用户可以继续使用自己的分区器-如果要实现粘性分区程序,可以使用onNewBatch方法来实现功能,如果他们不想使用该功能,则行为是相同的。
- 默认分区器在key=null,未设置partition值时,用户应看到延迟和CPU使用率是相同的或有减少的
测试结果
通常,与当前代码相比,粘性分区器通常会使延迟减少一半。 在最坏的情况下,也能达到默认代码标准。
随着分区的增加,看到更多的好处。 尽管如此,使用16个分区,仍然可以看到明显的好处。 在1000 msg / sec的吞吐量下,延迟仍然约为默认的一半。
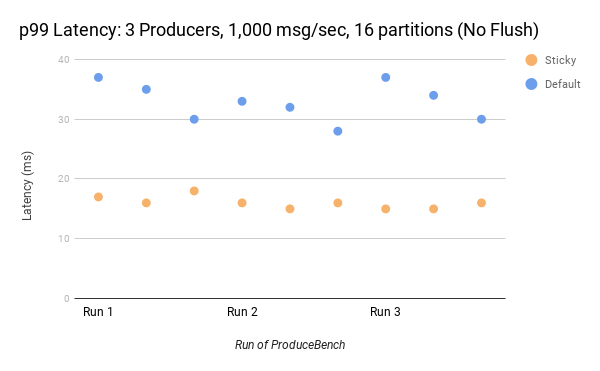
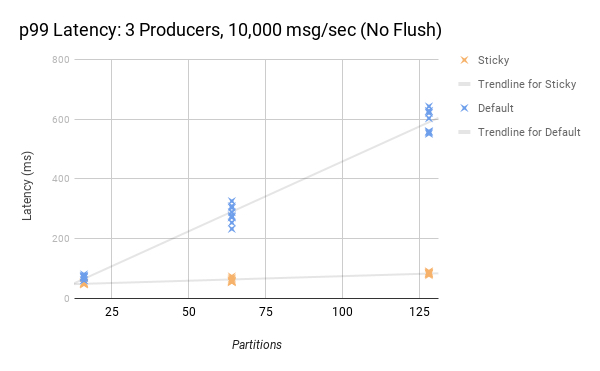
观察到的另一个趋势,尤其是在刷新情况下,随着发送的消息数量从低吞吐量增加到中吞吐量,等待时间减少更多。好处部分取决于每秒消息与分区的比率。
最后,在linger.ms不为零且吞吐量低到足以让默认代码需要在linger.ms上等待的情况下,显然有好处。例如,以1个生产者,16个分区和1000 msg / sec以及linger.ms = 1000运行时,粘性分区器的p99延迟为204,而默认值为1017。这大约是等待时间的1/3,这是因为批处理不必等待linger.ms。
除了延迟之外,与默认代码相比,粘性分区程序还发现CPU利用率下降。在观察到的情况下,与默认分区相比,粘性分区的节点通常会降低多达5-15%的CPU使用率(例如,从9-17%降低到5-12.5%或从30-40%降低到15-25%)代码的节点。
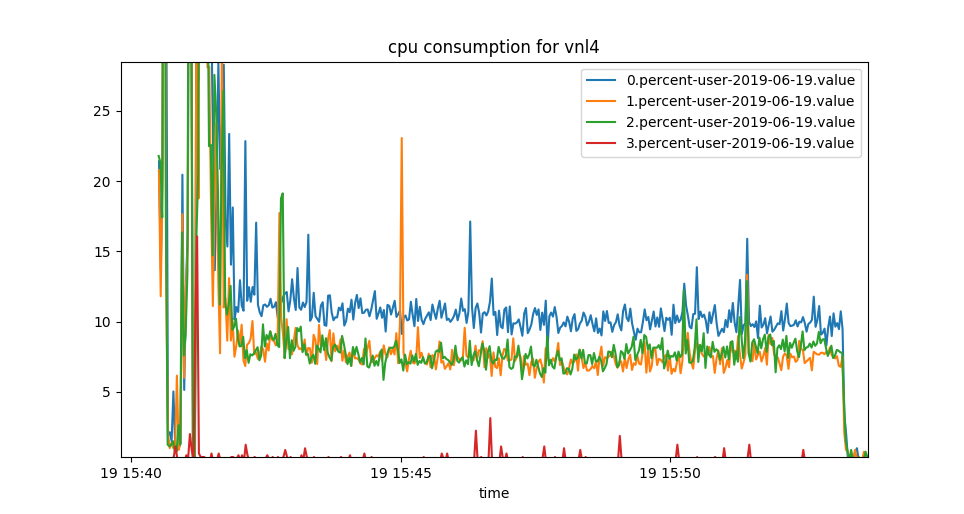
(Vnl是默认情况,而Chc是粘性分区程序。这是1个生产者,16个分区,10,000 msg / sec无刷新情况的结果。)
拒绝选择
拒绝选择可配置的粘性分区器的原因:测试表明,粘性分区程序在cpu利用率和延迟方面均达到或优于默认分区。 将粘性分区程序设置为可配置功能意味着某些用户可能会错过此有益功能
拒绝选择基于时间变化粘性分区的原因:变更时间将根据吞吐量而有所不同,需要针对不同的情况进行设置,吞吐量可能不一致